
Seit mehr als einem halben Jahrhundert steht OCR – Optical Character Recognition (optische Zeichenerkennung) – für eines: Maschinen, die einzelne Zeichen entschlüsseln. Von den frühen Schablonen in den 1960er Jahren bis hin zu den statistischen Engines der 2000er Jahre hat OCR das Lesen immer als mechanischen Prozess betrachtet. Es segmentierte Text in zeichenförmige Fragmente und versuchte, deren Bedeutung Buchstabe für Buchstabe zu analysieren. Aber diese Ära neigt sich nun dem Ende zu. Moderne Systeme lesen Zeichen überhaupt nicht mehr – zumindest nicht einzeln. Sie lesen Wörter, Phrasen und sogar Bedeutungen. OCR hat sich zu etwas grundlegend anderem entwickelt, und dieser Wandel sorgt für ein neues Maß an Genauigkeit, Geschmeidigkeit und Natürlichkeit, das frühere Generationen nicht erreichen konnten.
Das hat Skilja mit Lesa erschaffen, unserem Deep-Learning-System auf Transformer-Basis, das so konzipiert ist, dass es wie Menschen liest: ganzheitlich, kontextbezogen und intelligent.
Ein kurzer Rückblick: Von Zeichen zum Kontext
Die traditionelle OCR begann als analoger Prozess (daher das O = Optisch) und durchlief mehrere Phasen:
- 1950s–1980s:Starre Schablonen – nur bei makellosen maschinengeschriebenen Seiten effektiv.
- 1990s:Merkmalsextraktion und frühes maschinelles Lernen – besser, aber immer noch anfällig.
- 2000s–2010s:Statistische Modellierung und verbesserte Analyse-Workflows – gut genug für Bücher, gedruckte Formulare und eingeschränkte Handschrift, aber immer an Zeichen gebunden.
Selbst im besten Fall blieb die klassische OCR ein Ratespiel. Sie verwechselte die 1 mit dem Buchstaben l, verwandelte Flecken in Glyphen und hatte Schwierigkeiten mit allem, was außerhalb ihrer engen Erwartungen lag. Vor allem mit Handschrift.
Das Problem waren nicht bessere Algorithmen, sondern Zeichen – aber Menschen lesen Wörter und keine Zeichen, wie jeder bestätigen kann, der schon einmal einem Kind beim Lesenlernen zugesehen hat.
Der Wandel durch Deep Learning: Von der Entschlüsselung von Formen zum Verständnis von Sprache
Transformer haben alles verändert. Anstatt Zeichen zu interpretieren, interpretieren transformerbasierte Modelle Sequenzen, Kontext und sprachliche Wahrscheinlichkeit. Sie betrachten Text nicht als isolierte Formen, sondern als Teile von Sätzen, Absätzen und Konzepten.
Dadurch kann Lesa:
- ganze Wörter erkennen, nicht nur Buchstaben,
- den umgebenden Text als Kontext nutzen,
- die Kohärenz über ganze Seiten hinweg gewährleisten,
- und sich an verschiedene visuelle Stile anpassen.
Lesen wird zu einer Aufgabe des Sprachverständnisses und nicht zu einer Aufgabe der Pixel-Entschlüsselung.
Lesa: Entwickelt für Intelligenz auf Wortebene
Lesa wurde von Grund auf dafür entwickelt, ein Dokument als sprachliches Gebilde zu behandeln. Mithilfe einer Transformer-Architektur, die mit vielfältigen Texten und realen Bildern trainiert wurde, fragt Lesa nicht: „Was ist das für ein Zeichen?“, sondern: „Was bedeutet dieses Wort – und wie passt es in den Satz?“ Das ist wichtig, da wir nun:
- Deutlich weniger Fehler haben: Keine Fehlerkaskaden mehr durch einzelne Zeichen.
- Natürliche Ausgabe erreichen: Saubere Abstände, korrekte Zeichensetzung, zusammenhängender Text.
- Robustheit von Schriftart und Layout gewährleisten: Funktioniert bei formatiertem Text, unordentlichen Belegen, Tabellen und mehrspaltigen Seiten.
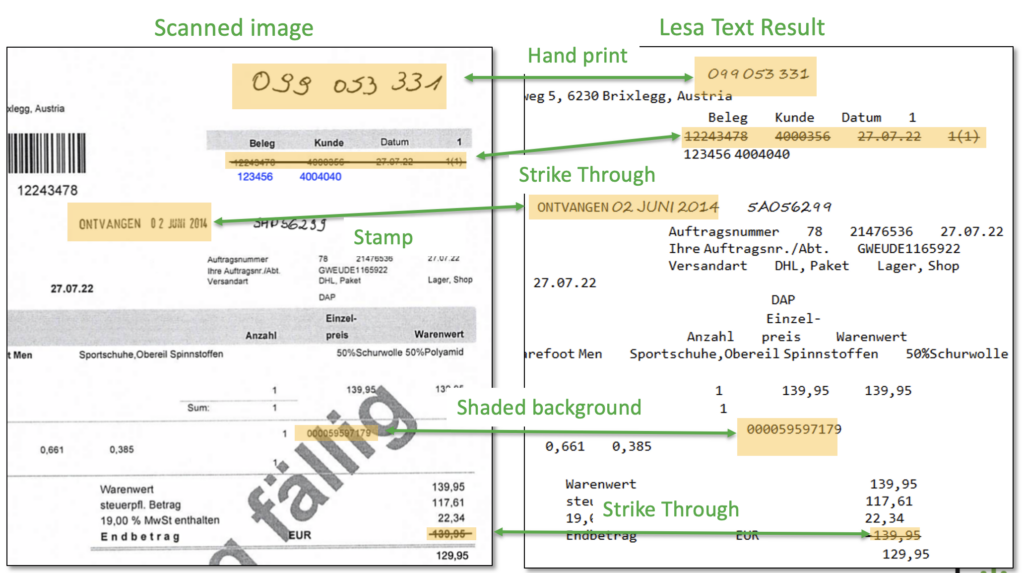
Eines der erstaunlichsten Ergebnisse des Verständnisses auf Wortebene ist, dass gebundene Handschrift – wie sie in Formularen, Notizen, Krankenakten, Lieferscheinen und Unternehmensunterlagen zu finden sind – nun viel besser funktionieren. Das bedeutet, dass unordentliche Großbuchstaben, mit Kästchen gefüllte Handschriften und halb gedruckte Formulare plötzlich gut lesbar sind. Die Handschrifterkennung ist plötzlich zum Greifen nah und wird routinemäßig angewendet.

Dies als „das Ende der OCR“ zu bezeichnen, ist keine Übertreibung. Es ist eine technische Anerkennung dessen, was sich verändert hat.
Traditionelle OCR = Zeichenerkennung, Moderne OCR = Sprachverständnis
Lesa gehört zu einer neuen Generation von Systemen, die Dokumente so lesen, wie Menschen es tun – indem sie Wörter interpretieren und nicht Symbole entschlüsseln.
OCR, wie wir es kannten, ist vorbei. Etwas Besseres hat es ersetzt. Lesa steht für diese neue Ära.