
The approach to improve OCR on a given document is very similar to human capabilities of adapting their cognitive capabilities to a specific sample. Just imagine that you see a document with very difficult handwriting. In the begining you will be able to distinguish some of the more distinct characters which in turn allow you to conclude the meaning of other characters as you can derive them from the characteristics of the writer. The same is done in unsupevised machine learning in the OCR Accuracy extension. We use object detection and classification to create clusters of all possible characters on a specific page and then use well recognizable characters to automatically label these clusters with their meaning (e.g. these are all capital “E”). From these a prototype can be derived and then applied in a second round to all the unknown characters. This helps the system to identify even deteriorated or distorted samples confidently thus boosting OCR quality.
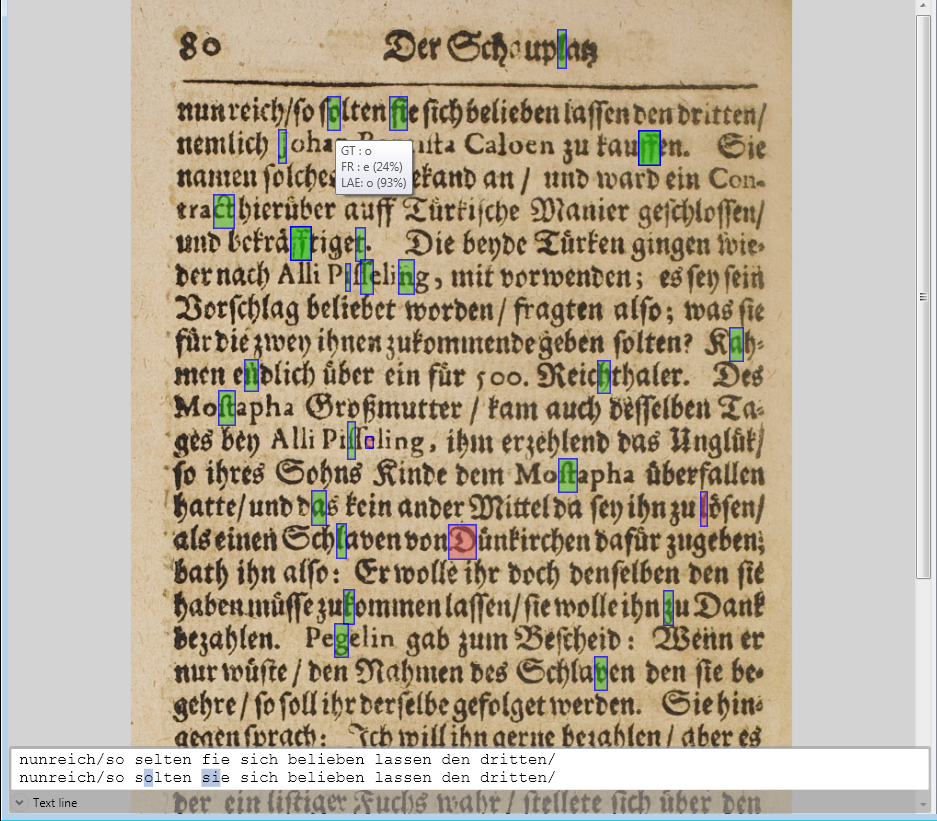
An example for a very old book is shown below displayed in our test and benchmark tool, the Accuracy Extension (AE) Studio. The green blocks highlight characters that have been corrected by the AE. In the tooltip you can see that in the first line in the word “solten” the character, which is an “o” in GT (ground truth), has been incorrectly recognized as “e” but has been corrected back to an “o” by AE. The text line shows the difference between the first normal OCR pass and the corrected result for the full line.
Another example is a typical old typewriter document (actually a telegram). All the faint characters have been well corrected. The text line at the bottom shows the comparison between original OCR and the magically corrected result.


A more complex example is the recognition of a complete old Newspaper page as shown below. This page contains 16.837 characters. This is an advantage because a high number of available character is beneficial for the automatic creation of good protoypes which in turn can be used to improve the quality.

In this case the first pass of OCR with FineReader 11 (from ABBYY) yields a decent quality of 78,4% correct characters when compared to a manually corrected ground truth file. If the AE OCR booster is initialized by unsupervised learning (default init) the recognition rate goes up by 6% to 84.5%. If in addition we use the ground truth of another page of the same newspaper for the learning step the system achieves an improvement of more than 10% to 88,7%.
These are promising first results for improving OCR on difficult documents using unsupervised machine learning techniques. The project is ongoing and will for sure yield even better results in the coming year, allowing researches to access cultural heritage easier and faster.

This project is funded by the Federal Ministry of Education and Research (BMBF) of Germany and the European Union under the project OptO-Heritage and grant number 01QE140.