
Editor’s note: This is a guest post from Cláudio Chaves from TCG Brazil
Recent advances in the auto-classification technologies – as described in this blog – have provided a substantial manual labor reduction for several companies related to physical preparation, classification and separation of documents into its operations. Although these advances have achieved tangible results in optimizing document centric workflows, there is still a gap in the aspect of classifying and tracking paper documents. This is especially important in some countries where physical documents are subject to different retention policies based on legal requirements. A certain amount of documents must be retained physically for a varying number of years based on the document type determined by classification.
Some capture applications are able to identify document types using barcode at scan time and using auto-classification or barcode content, apply different rules to separate and classify the document images. In the digital world everything is straightforward and works pretty well, but if you need to track and trace the same documents physically until the final archiving step is completed, it always becomes a challenge, especially into a large scale operation with tons of documents.
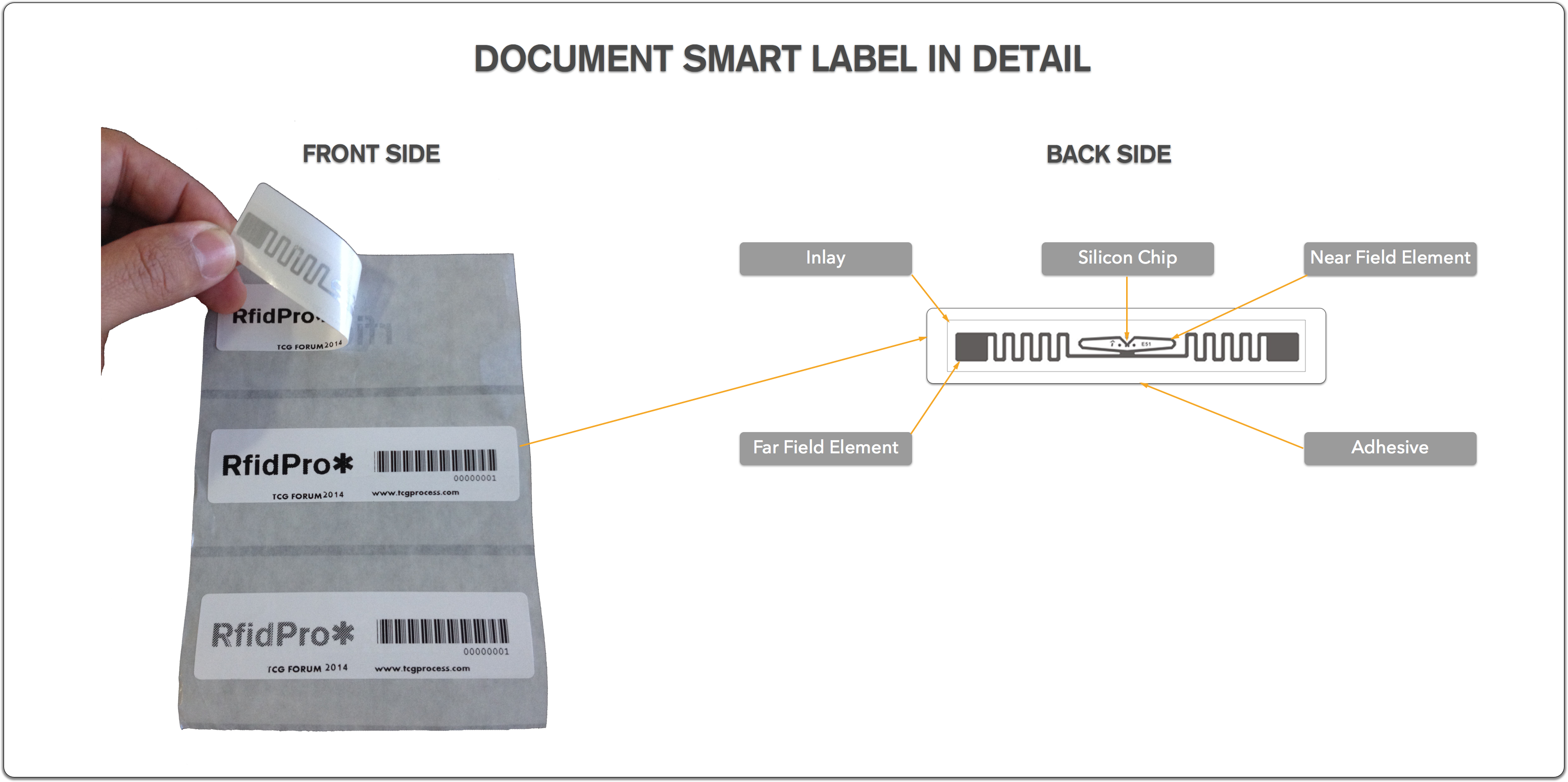
RFID is an acronym for Radio Frequency Identification, and it is also considered a generic term denoting the ability to identify an object remotely. It means that the information is transmitted via radio waves and does not require line-of-sight or contact between the reader and the tags. RFID technology provides great benefits through the combined use of a barcode, a microchip and an antenna, encapsulated into a tag, also called smart label. The radio waves are sent from a reader and then picked up by a tag that signals back its unique number called EPC (Electronic Product Code). The presence of a tagged folder/document is seen at a reader’s specific location, and this information can be reported to the tracking software that updates a records management database, an ECM repository or even a document capture platform.
Due a high reading speed and the capacity to identify an item even without visual access to the document, RFID technology makes it possible to quickly read a stack of tagged folders and documents even when they are stored inside a card box. In this way, it is possible to perform an automatic check-in of a ton of documents without any human intervention. Additionally it is also possible to inspect document containers like card box and folders at the receiving and delivering points, checking if all the required document classes are really there.
Just like barcodes, RFID technology allows to store a free encoding data schema into the EPC memory, on the other hand, it is always suggested to use a standard, to avoid a proprietary encoding. There are now a few international standards available for different types of objects, such as fixed assets, returnable assets, trade items, documents, etc. These standards have been developed by GS1, an international non-profit association, aiming efficiency improvement, higher items visibility and interoperability between the whole chain.
The EPC data schema GDTI (Global Document Type Identifier) specified by GS1, was developed to identify documents, including the class or type of each document. GDTI can be encoded in a 1D/2D barcode, stored into an EPC memory or printed directly on the document. Companies can use the GDTI as a method for identification and registration of documents and related events. They can also use the GDTI for information retrieval, document tracking, electronic archiving or even to prevent fraud and document falsification.
All these standards were specified based on the EPCGlobal framework, which describes the relation between different RFID components such as hardware, software and data interfaces. Based on the context of this article, we are referring about passive RFID. This technology does not use batteries and works with UHF frequency. Based on this specification, the objects can be identified not only in a near field, but also in a far field area, achieving up to 10 meters far, depending on the type of the object, the tag, antenna and the reader.
The combination of auto classification technologies and RFID tagged documents makes it possible to match the classification results, physically and logically.Given the physical classified document class, it is possible to define and choose the most appropriate document container (e.g. card box, folder, etc.) and pass the parent document class to the image/content classification engine to perform a deeper classification.
At the end of the process, we can match the results and track the both versions (image and paper) during the entire flow. This is can be achieved without physical contact with the paper document. Imagine that you get a box of paper from a remote location for archiving. If the documents have been classified and RFID encoded then within a second you can check the completeness of the physical archive and stow them away. If all of this happens with your capture process automation system you have a tight combination of auto-classification with physical sorting of paper – solving this last obstacle to full automation.
There are still several interesting RFID use cases for documents, such as automatic check in/out, hunting, inventory, exits, etc. which will become more and more popular very soon with the decreasing costs of the technology and the advances of new concepts like IoT (Internet of Things).
Links:
RFID: http://en.wikipedia.org/wiki/Radio-frequency_identification
GS1: http://www.gs1.org/about/overview
EPCGlobal Framework: http://www.gs1.org/gsmp/kc/epcglobal
GDTI: http://www.gs1.org/barcodes/technical/idkeys/gdti

####
Cláudio Chaves is Managing Director at TCG Brasil in Santana de Parnaíba, São Paulo, Brazil. He has many years of rich experience in the document processing applications especially in the South America market.