
In principle it is possible to train enough representative samples to create a classification scheme that is totally generic for a specific purpose. This is what humans do all the time.
Reading a text and correctly classifying it manually into a given category is a task that is achieved by any data entry operator after a little bit of training. Sometimes for complicated topics the training needs more time and is more demanding as is the case for example for medical ICD10 coders. You would imagine that a machine learning algorithm can achieve the same thing faster and more precisely if only enough text samples are provided. This view is supported by recent research results from cognitive scientists who have found out that the acquisition of speech by babies is very similar to a Bayesian classifier. In fact babies learn to distinguish between different entities very quickly and are able to abstract from a concrete example to the generic feature of a concept (=class). It is proven that humans do not compare objects they see with stored images of objects but that they have a very effective feature reduction capability to abstract from the sample as we have shown above with the example of cars.
But it is also known that these systems fall short when the domain is very specific and the documents are very complex. It seems that in these cases manual data entry operators are much better and faster as they have additional knowledge about the domain and the world as such. The simple brute force statistical method fails more often with rising complexity.
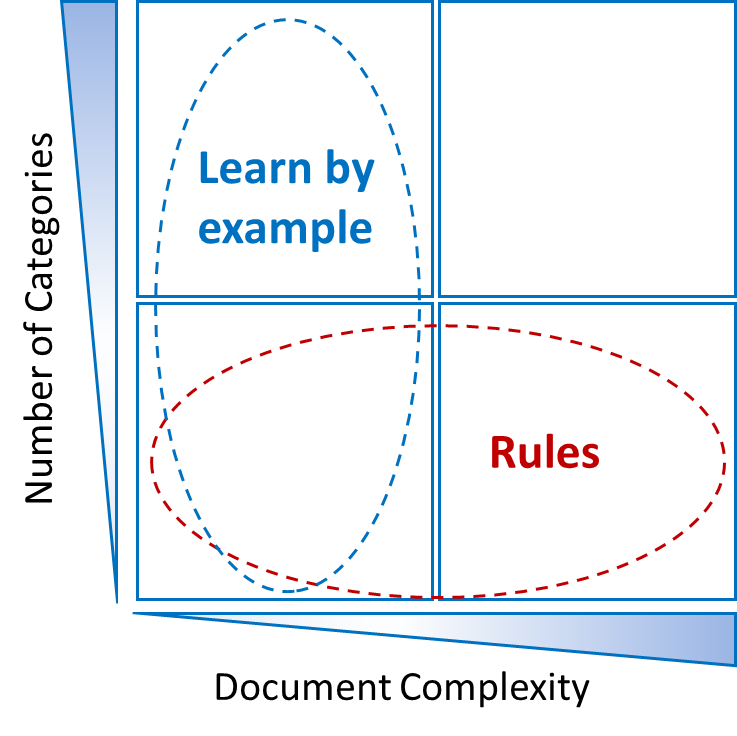
In the case of a low number of categories and high document complexity a carefully crafted rules based system is superior to any machine learning system. In fact also the pure statistical systems are now moving towards introducing semantic rules and world knowledge (so called ontologies) to overcome these difficulties.