
For more than half a century, OCR—Optical Character Recognition—has meant one thing: machines deciphering single characters. From early template-matching in the 1960s to the statistical engines of the 2000s, OCR has always approached reading as a mechanical process. It segmented text into character-shaped fragments and tried to analyze what each one meant, letter by letter. But that era is now ending. Modern systems don’t read characters at all—not individually. They read words, phrases, and even meaning. OCR has evolved into something fundamentally different, and this shift delivers a new level of accuracy, fluidity, and naturalness that previous generations could not reach.
This is what Skilja has done with Lesa, our deep-learning, transformer-based system designed to read like humans do: holistically, contextually, and intelligently.
A Brief Look Back: From Characters to Context
Traditional OCR started as an analogous process (therefore the O = Optical) and went through several stages:
- 1950s–1980s:Rigid template matching—effective only with perfect typewritten pages.
- 1990s:Feature extraction and early machine learning—better but still brittle.
- 2000s–2010s:Statistical modeling and improved analysis workflows—good enough for books and printed forms and constrained hand print, but always character-bound.
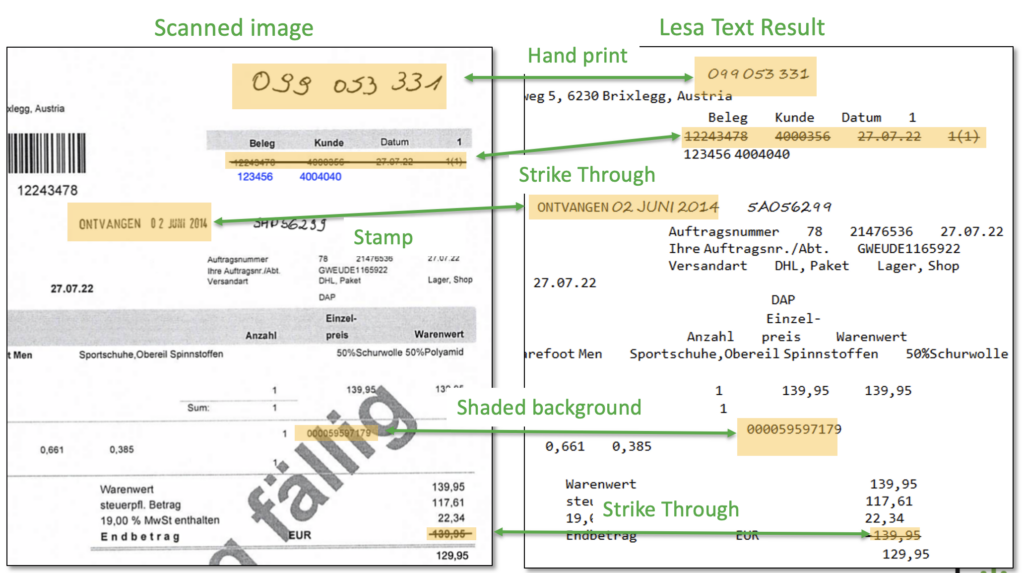
Even at its best, classical OCR remained a guessing game. It mistook 1 for l, turned smudges into glyphs, and struggled with anything outside its narrow expectations. Especially handwriting.
The problem wasn’t better algorithms—it was characters – but humans read words and not characters as anyone who has watched a child learn to read will confirm.
The Deep Learning Shift: From Decoding Shapes to Understanding Language
Transformers changed everything. Instead of interpreting characters, transformer-based models interpret sequences, context, and linguistic probability. They don’t see text as isolated shapes but as parts of sentences, paragraphs, and concepts.
This allows Lesa to:
- recognize entire words, not just letters,
- use surrounding text as context,
- maintain coherence across full pages,
- and adapt to different visual styles.
Reading becomes a language-understanding task, not a pixel-decoding task.
Lesa: Built for Word-Level Intelligence
Lesa is designed from the ground up to treat a document as a linguistic landscape. Using a transformer architecture trained on diverse text and real-world images, Lesa doesn’t ask, “What is this character?” It asks, “What does this word say—and how does it fit into the sentence?” This matters since now we have:
- Far fewer errors: No more character-by-character error cascades.
- Natural output: Clean spacing, correct punctuation, coherent text.
- Font and layout robustness: Works across stylized text, messy receipts, tables, multi-column pages.
One of the most transformative outcomes of word-level understanding is that constrained handwriting—the kind found in forms, notes, medical records, delivery slips, and corporate paperwork—now works much better. This means that messy capital letters, box-filled handwriting, and half-printed forms suddenly become highly readable. Handwriting recognition suddenly is at our fingertips and routinely applied.

Calling this the “end of OCR” isn’t hype. It’s a technical recognition of what has changed
Traditional OCR = character recognition
Modern OCR = language understanding
Lesa is part of a new generation of systems that read documents the way humans do—by interpreting words, not decoding symbols.
OCR as we knew it is over. Something better has replaced it. Lesa represents this new era.