
Classification deals with the categorization of objects. In our process automation and digitization world, we often think of the objects as complete documents that need to be classified. Of course, it is important to understand what the type of a document is and automatic classification can determine exactly this. But documents in a business context normally are complex and not homogenous. As a person when you get a multipage document you typically will browse through it to see what is in it to understand what it is about. A document in an envelope or a manila folder that you receive on your desk may consist of an opening letter, some notes, then the real important document, like for example the court order, and maybe attached some standard forms. To understand which process to initiate and what to do with the document you will therefore look at the pages and decide how you can determine from their content what this is all about. Maybe even two or more processes originate from different pages within one document where you might need to answer a request from one page and execute a payment from another page.
Laera Classifier – Page Classification for Claims Processing
This is exactly what page classification in document understanding is able to provide automatically. Instead of looking at the document as a whole the algorithm will classify page by page and derive decisions from the results. This is much more granular than taking only the complete document. And it is different from automatic document separation which is physically splitting the document. Of course, separation is another option based on page results, but it is error prone and risky as the document is ripped apart maybe incorrectly. Often this is not at all necessary but it is sufficient to structure and digitize the document page-wise to achieve the process goals intended.
Page classification requires a solid infrastructure and understanding of physical documents. We provide this with the Laera Classification Framework that inherently understands structured documents. Going even further would be paragraph and sentence classification but this will be a topic for another article. In Laera you can simply define a page classification scheme alongside the document classification. And you can even use the page classification results to determine the document type (e.g. by majority rule or by priority rule).
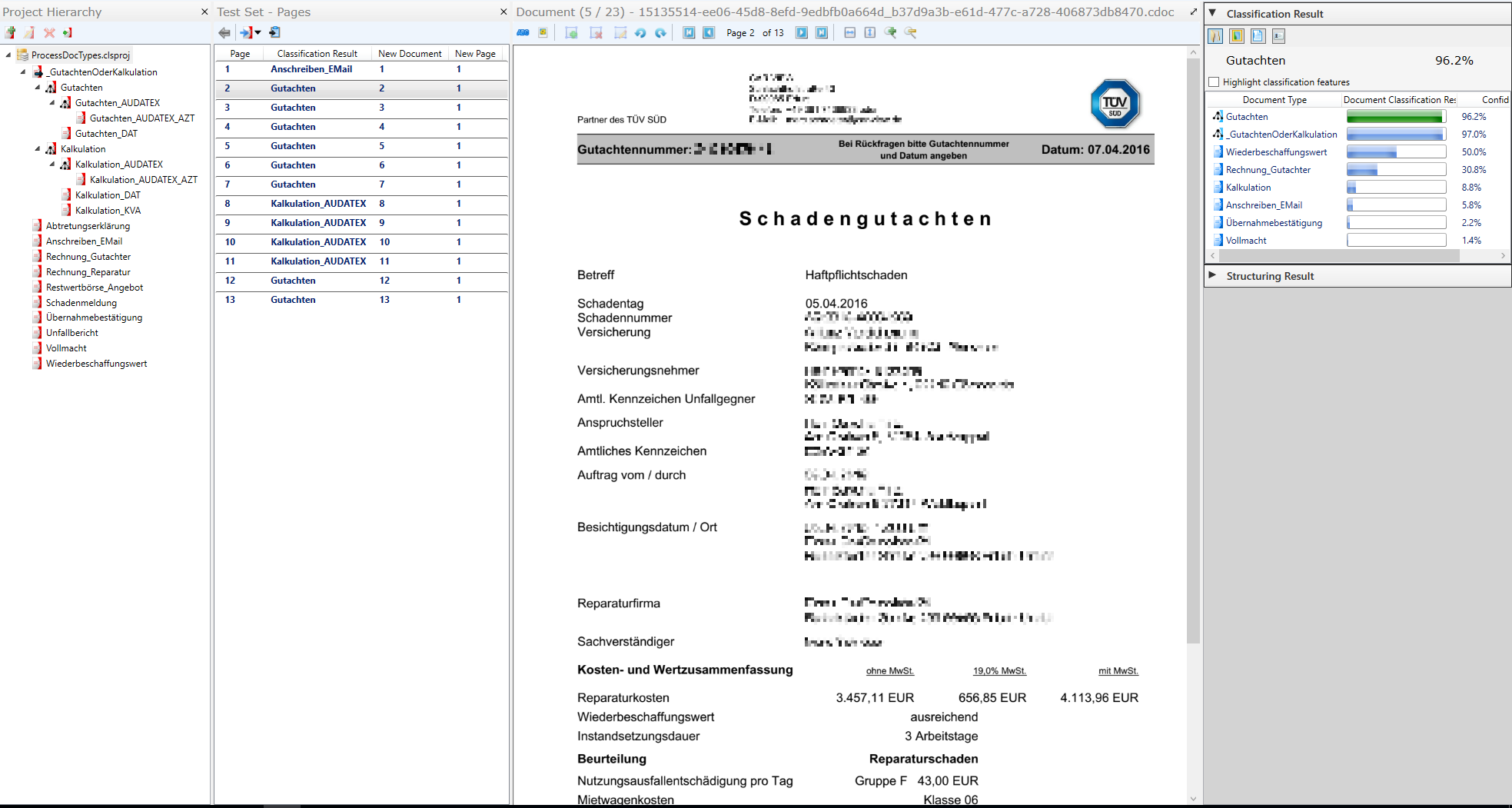
An example of a real-life project that is in production since more than a year is shown above.
In this case the customer receives thousands of car insurance claims per day. These are 10 to 50 page documents that contain all different kind of pages, as examples:
- Covering letter or e-mail (“Anschreiben”)
- Attorney’s letter
- Expertise (“Gutachten”)
- Calculation of repair (“Kalkulation”)
- Declaration of Assignment (“Abtretungserklärung”)
- Photos
Laera Classifier is able to automatically determine all of these types with a rate in the high 90%. Photo detection tags all photos and hides them for the following recognition steps as they are unnecessarily blocking OCR and extraction steps otherwise. The page classification results allow to structure and reorder the document in an optimal way for subsequent extraction of data from the different page types. Being able to define specific extraction for each page type leads to a significant increase in extraction quality and speed. It also greatly eases the task for the clerks in the subsequent process steps as they already receive a structured document (in this case a PDF that is assembled) with tags and always in the same order.
In such way page classification plays an important role in streamlining the process getting a bit closer to the way how a person would look at the document and work from it.