
One of the frequently overlooked and really difficult problems in document automation, which is also really annoying in daily processing, is the automatic separation of a stack of documents into single meaningful documents and assignment to a document class. In traditional scanning processes this is often achieved by manual preparation of the paper and sticking a barcode as a document separator on each first page. But this is labor intensive and error prone. In addition as we are going more and more digital, even with paper based processes, normally the processing facility does not have access to the paper any more. So the goal would be to simply scan the whole stack and have it separated by an intelligent algorithm.
Fortunately this is readily available today for example from the Skilja technology stack as a built in feature into the Laera classifier. This does not say it is easy. It requires quite some experience and infrastructure to manage several interdependent steps of classification and separation in a stable and reliable way. This is what Laera provides out of the box.
How does document structuring work in principle? Well, in exactly the same way (our credo!) as a human would do it. Go through the stack page by page, determine what page type it is, if it is related to the previous page or if a new topic/form starts. Then check page numbers for security if they are present. If in doubt, go back one or a few pages to check back and then make your decision to separate.

Laera Document Separation
In AI classification, what Laera is, this is built into a sequence of algorithms. The system is trained on a sample that is already correctly separated. Laera does learn for each page if it is a first, a middle, and end or a single page. The user does not have to specify this explicitly as the Laera AI finds that out automatically from the samples and hides this complexity from the users. The training interface just requires you to drop the single documents into the training set. It is not required to have an exact number of pages (range) for each document type. Laera automatically takes into account that these can vary for each document type. However if you know you can also restrict allowed pages for example for single page forms that are always single page.
Laera will then learn the structure and apply it to the whole document stack of unseparated single pages during runtime. Each page is analyzed. A second classifier (we could call it a “meta-classifier”) will then take these results and find the most probable separation based on the trained model. So even if a first page has not been identified as a first page there is a chance that the meta-classifier still will see it as more probable to be a first page and correctly separate. A third classifier will then determine the document type for the separated documents. As usual in Laera all this is very fast and a separation of a stack of 200 pages with 150 document types takes less than 30 seconds in total.
The example below shows the results from separation of a mortgage application stack with 153 pages and classification in 244 document types. The horizontal lines indicated the found separators and the “New page” column shows the new numbering of pages in the separated documents.

Laera Mortgage Separation Result (click on image to see full screen)
The detail view of the separation result for one page nicely shows how the separation algorithm came to a decision for the first page of a URLA supported in addition by the detected page count on the page (“Page 1 of 9).
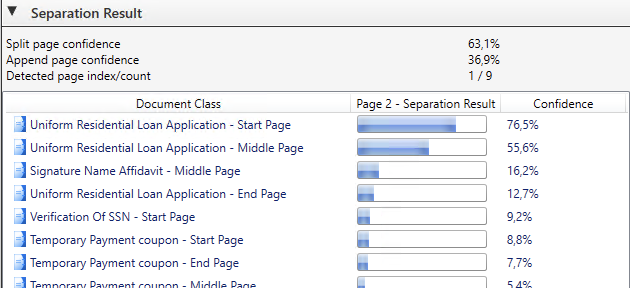
Laera Mortgage Separation Details
Training of this model takes about 10 minutes so it is easy to frequently test and refine it. All this can be done by the end user and does not need an AI engineer.
Quality is very important and Laera makes sure to bias towards precision to no errors are made and allow the workflow to show unconfident separations to a user for decision. In a project that was done 18 months ago for a large Swiss insurance company Laera achieved an automation rate of 87% with an error rate (false positive) or 0.14%. Still of course each separation result needs to be checked and the correction results will be used by Laera online learning to improve the model.
But overall the reduction of work in separation and the increase in quality is very measurable and yields huge benefits. All this is available either on premise or as cloud service to be used through RPA or RESTful API in any backend. Let us know if you are interested and we can show you a demo. Also a setup with your own documents is easily achievable with little effort. Contact is info (at) skilja.com.